そのモデル、古いっすよ。
GPT4ALLの公式ページやLangChainの公式リファレンスを参考にコードを並べて、確かにモデルに”gpt4all-lora-quantized.bin”(DirectLink)を指定しているのに、「それ古いっすよ」と軽くあしらうようなエラーが何をやっても帰ってくる。もうあたし実家に帰らせてもらいます。(水星の魔女season2始まったのに見れてないし)
そう諦めて、開きに開いてアイコンだけが並ぶFirefoxのタブを一つ一つ閉じている最中、ふと、そういや試してなかった事があったなと、半ば投げやりな気持ちで挑んだ結果がドンピシャリ。就職氷河期世代を時空の闇に葬りさるかのような「古いっすよ」という呪いの赤文字(エラー)が消えてくれちゃったので、足跡として残しときます。
(エラーのログとか取ってる余裕なかったので、意訳です。ごめんちゃい)
結局、何のエラーだったの?
結論から言うと、エラー表示の通り使用していたbinファイルの形式が古かったわけです。古いっつってもほんの二週間前に更新されてたりするので、この界隈の進み方と進ませ方は、ほんとえげつないなあって感じですね。進めろバンバンで、ユーザーフレンドリーとか後方互換とか、そんなの関係ぇねぇ!わけですね。
どうやら個人のユースケースにVRAM20GB超えるようなGPUねーから、って前提に立って、どのモデルもとにかく軽く(かつ高品質に)できるよう試行錯誤するのが盛り上がっているようでして。
GPT4ALL始めLlama系は、そっち方面がかなり活発なようでして。そりゃそうです。せっかくfacebookが少ないパラメータでも高品質なモデルをオープンにしてくれわけですから。
そういった動きのなかで、現在ggmlなるフォーマットが使われだしているそうなのですよ。はい。
解決のために行ったこと。
いや、ほんとはこういうの、ちゃんと書いたコードとエラー載せるもんなんすけどね。
コードったって、GPT4ALLにジェネレートしてもらうだけなので、公式さんの出してる例ほぼそのまま。
なお、私の環境は、win10。cpu2.5GHz、16GBRAM。一応、お情け程度に2GBVRAMのビデオカードが付いたちょっと古めのノートPCです。pycharmで仮想環境つくってます。
STEP1.流れ流れて、pyllamacppにたどり着く。
ざーっくり読んでいった結果、なんとなくこの辺の説明に従えば良さげかなと、ggmlの付いたファイルをリンクからダウンロードしてぶっ込んでみるも、にべもなく「古いっす」と言われてしまい詰む。
STEP2.仕方なく説明に従ってpyllamacppをインストールしてみるも、それだけでは何も変わらず。サンプルコードもここのを参考にしてみてもやっぱり「古いっす」とか「このモデルは読めないっす」の繰り返し。俺が長男じゃなかったらとっくに(以下)
STEP3.どうやらllama.cppというのがモデルを軽量化する為にあるという情報を掴み、中にあるコンバーターの使用を試みるもDos窓だけでて即消滅。ファイルに変化なし。
(このとき、peftの出すエラーをllama.cppのコードを書き換えて解消させる、みたいな情報を目にしたので挑んでみたが、これも結果的に無関係だった…涙)
STEP4.もういい、もう、いいんだよ…。と優しく囁いた辺りでふと、「古いモデルのコンバートは試してないな」と思いつき、即実行。しかし「古くないっすけど、なんかテンソルに変なの混じってて読めないっす」と、惜しい、なんか惜しい、そして口惜しい結果に。
STEP5.いよいよ実家に帰ろうかと荷物(ブラウザのタブ)を畳んでいる最中、そういえば、GPT4ALLのモデルに、「Unfiltered」とそうでないのがあったよなぁ…。と思い至る。そう、どうせならとフィルターなしの方を使おうと思って3でコンバートに掛けたのであった。
ダメ元で通常版をコンバートして、コードにぶっこむ。
……………………………………。

ふぅぅぅぅうううううううはあああああああ!!!!!!
きた、きましたよ。pyファイルからCUI起動がついに出来ました。
今日一日が無駄にならなくてよかった。。。
まあ、LangChainと連携できるかどうかは、また別な話なんですけどね笑
少なくとも、GUIなんかを作って使い勝手をよくしたりもできるようになったのは僥倖。
pyllamacppでのコンバート(pyllamacppのサンプルコードでジェネレートするケース)
一応、ざっくりご説明。
事前準備:公式の説明に従ってインストール(←おい)
用意するもの:gpt4all-lora-quantized.bin(古いぞと怒られるやつ)
tokenizer.model(llamaのトークナイザー。今回はHugging faceのdecapoda-research/llama-7b-hfから拝借)
以上。
公式の指示に従って
pyllamacpp-convert-gpt4all path/to/gpt4all_model.bin path/to/llama_tokenizer path/to/gpt4all-converted.binとやりたいところなんですが、pyllamacpp-convert-gpt4allと入れても自分の環境では動きませんでした。(なら載せるな)
ってなわけで、老眼の始まった目をこすりながらファイルを確認していく。
するとpyllamacpp/script/辺りに、convert-gpt4all.pyが見つかるはず。こいつを使います。
cmdもしくはpowerShellなんかでcdを駆使して当該フォルダまで移動。
(能力のない趣味でプログラム叩いてるだけの人間なので、直接実行できない涙)
んで、適当なフォルダを作成してbinとtokenizerを入れ、以下を実行。
./convert-gpt4all.py path/to/gpt4all-lora-quantized.bin path/to/tokenizer.model path/to/newname.bin(↑path/to/は各々のファルダパスだよ。諸々、それぞれの環境に合わせてね!)
ようは動けばいいんです。動けば。
すると、Dos窓にズラズラズラズラーって処理のログが流れていき、終わったら勝手に消えます。そして、newnameを付けたファイルが該当箇所に出来上がります。
んで、そいつを公式さんの説明通りのコードに打ち込めば勝ちです。
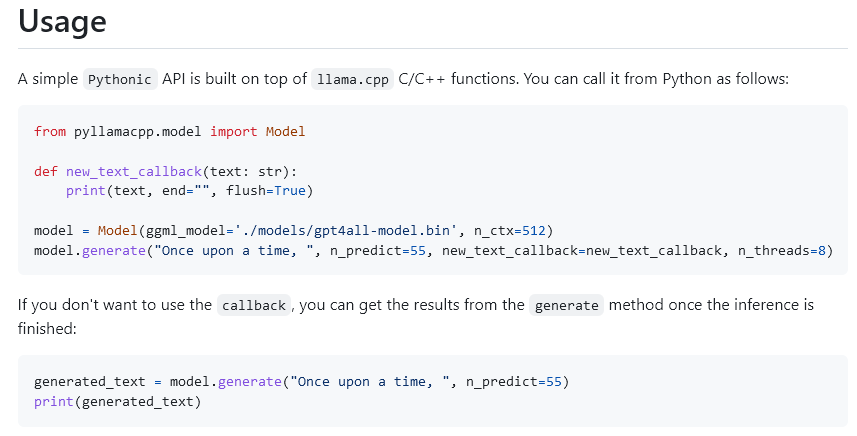
「./models/gpt4all-model.bin」のところを、コンバートしたやーつに変えてあげてくらはいね。(なんて丁寧な説明!)
これで一丁あがりってもんです。やったね!
LangChainはどこに消えた?
このあたりまで来て力尽きたので、また今度。
たしかLangChainの方からも「古いよ」って怒られたような気がしたので、今日の苦闘が生きてくると願いたい。
んでもさ、Llama系、商用不可なんだよね。
仮にG全君(※GPT4ALLのこと)がgoogle検索出来たりファインチューンが可能になったりしたとして、はてさて、なにに使ったら便利だろうか。今後の課題。
最後までお読みいただき、ありがとうございました。
コメント